

How to Scrape and Parse 600 ETF Options in 10 mins with Python and Asyncio
/Post Outline
- Intro
- Disclaimers
- The Secret to Scraping AJAX Sites
- The async_option_scraper script
- first_async_scraper class
- expirys class
- xp_async_scraper class
- last_price_scraper class
- The option_parser Module
- The Implementation Script
- References
Intro
This is Part 1 of a new series I'm doing in semi real-time to build a functional options data dashboard using Python. There are many underlying motivations to attempt this, and several challenges to implementing a tool like this from scratch.
- Where to get the data? Is it affordable? Easily accessible? API?
- How to parse the results?
- How to aggregate and organize the data for analysis?
- How to store the data? TXT, CSV, SQL database, HDF5??
- How often should it run?
- How to display the data? What dynamic graphic library to use? D3.js, MPL3d, Plotly, Bokeh, etc.?
These are some of the problems that need to be solved in order to create the tool.
In this post I show a current working solution to where to get the data, how to scrape it, how to parse it, and a storage method for fast read write access. We will scrape Barchart.com's basic option quotes using aiohttp and asyncio, both are included in Python 3.6 standard library. We will parse it using Pandas and Numpy and store the data in the HDF5 file format.
Disclaimers
This is primarily an academic exercise. I have no intent to harm or cause others to harm Barchart.com or its vendors. My belief is that, by facilitating knowledge sharing, we will increase the number of educated participants in the options markets; thereby increasing the total addressable market for businesses like Barchart and its vendors. By designing tools like this we improve our own understanding of the use cases and applications (option valuation and trading) and can provide better feedback to those in the product development process.
The Secret to Scraping Ajax Sites
First let's create a mental model of what AJAX really is.
So looking at this, we can say AJAX is a set of web development techniques to increase the efficiency and user experience during website interaction. For example, you go to a website with cool data tables on it. You want to change one of the filters on the data so you select the option you want and click. What happens from there?
In simply designed or older websites your request would be sent to the server, then to update the data table with your selected filters would require the server response to reload the entire page. This is inefficient for many reasons but one is that, often the element in need of updating is only a fraction of the entire webpage.
AJAX allows websites to send requests to the server and update page elements on an element by element basis negating the need for reloading the entire page every time you interact with the page.
This improvement in efficiency comes at the added cost of complexity, for web designers and developers and for web scrapers. Generally speaking the url you use to go to an AJAX page is not the actual url that gets sent to the server to load the page you view.
To build this understanding, let's look at a sample option quote page using the following link <https://www.barchart.com/stocks/quotes/spy/options>.
Warning: To follow along with the rest of this example you need access to developer mode in Chrome or its equivalent in other browsers.
Let's look behind the curtain so to speak. Click anywhere in the page and click inspect. Navigate to the Network tab in Chrome developer tools.
We're going to press F5 to reload the page and look for the following: Request Headers, and the Request URL.
We will need the Request URL and the Request Headers in order to construct our calls to the server a little later. Simply put, this is the secret! We can replicate our browser's behavior when it requests data from the server if we know the actual request url and the request headers. This will be made clearer in the next section.
The async_option_scraper.py Module
This is the key module for scraping the data. First the imports.
import asyncio
import aiohttp
first_async_scraper class
If you noticed when the page loads, it loads the nearest expiration date by default.
We know there are generally multiple expiration dates per symbol. However, some ETFs have weekly contracts, monthly, and/or quarterly. Instead of guessing the expiration dates, the first_async_scraper class scrapes the default pages so we can later extract the expiration dates directly from the page's JSON/dict response.
This class takes no initialization parameters.
# ================================================
# for first run only
class first_async_scraper:
def __init__(self):
pass
async def _fetch(self, symbol, url, session, headers):
"""fn: to retrieve option quotes as JSON
Params:
symbol : str(), ETF
url : str(), request url
session : aiohttp.ClientSession() object
headers : dict() containing header info
Returns:
response : JSON/Python Dict
"""
async with session.post(url.format(symbol), headers=headers) as response:
return await response.json(content_type=None)
async def run(self, symbols, user_agent):
"""fn: to aggregate response option quotes
Params:
symbols : list of str(), ETF symbols
user_agent : str()
Returns:
responses : list of JSON
"""
url = 'https://core-api.barchart.com/v1/options/chain?symbol={}&fields=strikePrice%2ClastPrice%2CpercentFromLast%2CbidPrice%2Cmidpoint%2CaskPrice%2CpriceChange%2CpercentChange%2Cvolatility%2Cvolume%2CopenInterest%2CoptionType%2CdaysToExpiration%2CexpirationDate%2CsymbolCode%2CsymbolType&groupBy=optionType&raw=1&meta=field.shortName%2Cfield.type%2Cfield.description'
headers = {
"Accept":"application/json",
"Accept-Encoding":"gzip, deflate, sdch, br",
"Accept-Language":"en-US,en;q = 0.8",
"Connection":"keep-alive",
"Host":"core-api.barchart.com",
"Origin":"https://www.barchart.com",
"Referer":"https://www.barchart.com/etfs-funds/quotes/{}/options",
"User-Agent":user_agent,
}
tasks = []
async with aiohttp.ClientSession() as session:
for symbol in symbols:
headers['Referer'] = headers['Referer'].format(symbol)
task = asyncio.ensure_future(self._fetch(symbol, url, session, headers))
tasks.append(task)
# gather returns responses in original order not arrival order
# https://docs.python.org/3/library/asyncio-task.html#task-functions
responses = await asyncio.gather(*tasks)
return responses
The workhorse function is run which calls the internal function _fetch. Inside the run function I've hardcoded a request url similar to the one we found before. I've also hardcoded the headers we found earlier as well. Notice both objects are string formats which can be dynamically updated with our ETF symbol.
The _fetch function takes the ETF symbol, the url string, session object, and our request headers and makes the call to the server returning the response as a JSON /dict object.
The run function takes a list of symbols, and a user agent string - more on this later.
The aiohttp package has a very similar interface to the requests module. We first create a ClientSession object which acts like a context manager. After creating the session object, we loop through each symbol using the asyncio.ensure_future function to create and schedule the event task. The gather function executes the tasks asynchronously waiting until all tasks have completed. It returns a list of JSON responses, each representing one ETF.
The Expirys Class
Once we have the list of responses we need to extract the expiry dates from each page source, collecting them for later use. The class is initialized with two parameters - a list of ETF symbols, and the list of page responses from the first scrape job.
It uses two functions. The internal function _get_dict_expiry takes a single response object and returns the list of expirations for a single symbol. The exposed function get_expirys loops through the list of ETFs and responses aggregating them into a dictionary. The dictionary keys are the ETF symbols and the values are lists of expirations for that symbol.
# ================================================
class expirys:
def __init__(self, ETFS, first_future_result):
"""Class to extract expiration data from Dict
Params:
ETFS : list of ETF symbol str()
first_future_result : list of response objects (dict/JSON) from the first scraper
"""
self.ETFS = ETFS
self.first_future_result = first_future_result
def _get_dict_expiry(self, response):
"""fn: to get expirations from response dict
Params:
response : dict/JSON object
Returns:
list() of date str(), "YYYY-MM-DD"
"""
if response['count'] == 0:
return None
else:
return response['meta']['expirations']
def get_expirys(self):
"""fn: to create dict with k, v = symbol, list of expirys
we have to do this b/c JSON/dict response data doesn't
contain symbol identifier
Returns:
dict(symbol = list of expiry dates)
"""
from itertools import zip_longest
expirys = {}
for symbol, resp in zip_longest(self.ETFS, self.first_future_result):
# we can do this because results are in order of submission not arrival
# gather returns responses in original order not arrival order
# https://docs.python.org/3/library/asyncio-task.html#task-functions
expirys[symbol] = self._get_dict_expiry(resp)
return expirys
xp_async_scraper class
The final scraper class is nearly identical to the first_async_scraper except for some additional arguments for the functions xp_run(), and _xp_fetch() to accept the expiry dates. Also notice that the hard coded URL in the xp_run function is slightly different in that it is formatted to accept the ETF symbol and an expiration date.
# ================================================
# async by url + expirations
class xp_async_scraper:
def __init__(self):
pass
async def _xp_fetch(self, symbol, expiry, url, session, headers):
"""fn: to retrieve option quotes as JSON
Params:
symbol : str(), ETF
expiry : str(), "YYYY-MM-DD"
url : str(), request url
session : aiohttp.ClientSession() object
headers : dict() containing header info
Returns:
response : JSON/Python Dict
"""
async with session.post(url.format(symbol, expiry), headers=headers) as response:
return await response.json(content_type=None)
async def xp_run(self, symbol, expirys, user_agent):
"""fn: to aggregate response option quotes
Params:
symbol : str(), ETF
expirys : list of date str() "YYYY-MM-DD"
user_agent : str()
Returns:
responses : list of JSON
"""
url = "https://core-api.barchart.com/v1/options/chain?symbol={}&fields=strikePrice%2ClastPrice%2CpercentFromLast%2CbidPrice%2Cmidpoint%2CaskPrice%2CpriceChange%2CpercentChange%2Cvolatility%2Cvolume%2CopenInterest%2CoptionType%2CdaysToExpiration%2CexpirationDate%2CsymbolCode%2CsymbolType&groupBy=optionType&expirationDate={}&raw=1&meta=field.shortName%2Cfield.type%2Cfield.description"
headers = {
"Accept":"application/json",
"Accept-Encoding":"gzip, deflate, sdch, br",
"Accept-Language":"en-US,en;q=0.8",
"Connection":"keep-alive",
"Host":"core-api.barchart.com",
"Origin":"https://www.barchart.com",
"Referer":"https://www.barchart.com/etfs-funds/quotes/{}/options",
"User-Agent":user_agent,
}
tasks = []
async with aiohttp.ClientSession() as session:
for expiry in expirys:
headers['Referer'] = headers['Referer'].format(symbol)
task = asyncio.ensure_future(self._xp_fetch(symbol, expiry, url, session, headers))
tasks.append(task)
# gather returns responses in original order not arrival order
# https://docs.python.org/3/library/asyncio-task.html#task-functions
responses = await asyncio.gather(*tasks)
return responses
last_price_scraper class
This class has the same structure and form as the other scraper classes except slightly simpler. The purpose of this class is to simply retrieve the basic html source for each ETF so that we can later extract the last quote price for the underlying equity.
# ================================================
# async get html page source
class last_price_scraper:
def __init__(self):
pass
async def _fetch(self, symbol, url, session):
"""fn: to retrieve option quotes as JSON
Params:
symbol : str(), ETF
url : str(), request url
session : aiohttp.ClientSession() object
Returns:
response : text object
"""
async with session.get(url.format(symbol)) as response:
return await response.text()
async def run(self, symbols):
"""fn: to aggregate response option quotes
Params:
symbols : list of str(), ETF symbols
Returns:
responses : list of text
"""
url = 'https://www.barchart.com/stocks/quotes/{}/options'
tasks = []
async with aiohttp.ClientSession() as session:
for symbol in symbols:
task = asyncio.ensure_future(self._fetch(symbol, url, session))
tasks.append(task)
# gather returns responses in original order not arrival order
# https://docs.python.org/3/library/asyncio-task.html#task-functions
responses = await asyncio.gather(*tasks)
return responses
The option_parser.py Module
Once we have all the data we need to be able to parse it for easy analysis and storage. Fortunately this is relatively simple to do with Pandas. The option_parser.py module contains one class-option_parser, and three functions-extract_last_price(), create_call_df(), create_put_df().
The option_parser class is initialized with an ETF symbol and the appropriate response object. The create dataframe functions extract the call/put data from the JSON/dict response, then iterates through each quote combining them into dataframes taking care to clean the data set and change the datatypes from objects to numeric/datetime where appropriate. The extract_last_price function is used to get the underlying quote price from the basic html source.
import pandas as pd
import numpy as np
# ================================================
class option_parser:
def __init__(self, symbol, response):
self.symbol = symbol
self.response = response
# ------------------------------------------------
# extract last price from html
def extract_last_price(self, html_text):
"""fn: extract price from html"""
reg_exp = r'(?<="lastPrice":)(\d{1,3}.{1}\d{2})'
prices = re.findall(reg_exp, html_text)
if len(prices) < 1:
return np.nan
else:
return float(prices[0])
# ------------------------------------------------
# create call df
def create_call_df(self):
"""fn: to create call df"""
json_calls = self.response['data']['Call']
list_dfs = []
for quote in json_calls:
list_dfs.append(pd.DataFrame.from_dict(quote['raw'], orient='index'))
df = (
pd.concat(list_dfs, axis=1).T.reset_index(drop=True)
.replace('NA', np.nan)
.apply(pd.to_numeric, errors='ignore')
.assign(expirationDate = lambda x: pd.to_datetime(x['expirationDate']))
)
df['symbol'] = [self.symbol] * len(df.index)
return df
# ------------------------------------------------
# create put df
def create_put_df(self):
"""fn: to create put df"""
json_puts = self.response['data']['Put']
list_dfs = []
for quote in json_puts:
list_dfs.append(pd.DataFrame.from_dict(quote['raw'], orient='index'))
df = (
pd.concat(list_dfs, axis=1).T.reset_index(drop=True)
.replace('NA', np.nan)
.apply(pd.to_numeric, errors='ignore')
.assign(expirationDate = lambda x: pd.to_datetime(x['expirationDate']))
)
df['symbol'] = [self.symbol] * len(df.index)
return df
The Implementation Script
Finally we can combine the modules into a script and run it. Note that this script requires the fake-useragent package. This package has a nice feature where it generates a random user agent string on every call. We need to do this so our requests are not blocked by the server.
The script imports a list of ETF symbols originally sourced from Nasdaq. Some of these symbols don't have options data, so they are filtered out. The script runs in the following order: basic html scraper -> first async scraper -> extracts the expiry dates -> xp async scraper which aggregates all the option data -> parses the collected data into a dataframe format -> downloads and inserts any missing underlying prices -> then saves it to disk as an HDF5 file.
import os
import sys
import pandas as pd
import pandas_datareader.data as web
import numpy as np
import time
import asyncio
from fake_useragent import UserAgent
'''set path variables'''
project_dir = "YOUR/PROJECT/DIR"
sys.path.append(project_dir)
import async_option_scraper
import option_parser
# ================================================
today = pd.datetime.today().date()
# ================================================
file_start = time.time()
print('\nAsync Barchart Scraper starting...')
# --------------- \\\
# import symbols
FILE = project_dir + 'ETFList.Options.Nasdaq__M.csv'
ALL_ETFS = pd.read_csv(FILE)['Symbol']
drop_symbols = ['ADRE', 'AUNZ', 'CGW', 'DGT', 'DSI', 'EMIF', 'EPHE', 'EPU', 'EUSA', 'FAN', 'FDD', 'FRN', 'GAF', 'GII', 'GLDI', 'GRU', 'GUNR', 'ICN', 'INXX', 'IYY', 'KLD', 'KWT', 'KXI', 'MINT', 'NLR', 'PBP', 'PBS', 'PEJ', 'PIO', 'PWB', 'PWV', 'SCHO', 'SCHR', 'SCPB', 'SDOG', 'SHM', 'SHV', 'THRK', 'TLO', 'UHN', 'USCI', 'USV', 'VCSH']
ETFS = [x for x in ALL_ETFS if x not in set(drop_symbols)]
# ================================================
# GET HTML SOURCE FOR LAST SYMBOL EQUITY PRICE
# ================================================
t0_price = time.time()
# --------------- \\\
loop = asyncio.get_event_loop()
px_scraper = async_option_scraper.last_price_scraper()
px_run_future = asyncio.ensure_future(px_scraper.run(ETFS))
loop.run_until_complete(px_run_future)
px_run = px_run_future.result()
# ------------- ///
duration_price = time.time() - t0_price
print('\nprice scraper script run time: ',
pd.to_timedelta(duration_price, unit='s'))
# ------------- ///
# create price dictionary
px_dict = {}
for k, v in zip(ETFS, px_run):
px_dict[k] = v
# ================================================
# RUN FIRST ASYNC SCRAPER
# ================================================
t0_first = time.time()
# --------------- \\\
ua = UserAgent()
loop = asyncio.get_event_loop()
first_scraper = async_option_scraper.first_async_scraper()
first_run_future = asyncio.ensure_future(
first_scraper.run(ETFS, ua.random)
)
loop.run_until_complete(first_run_future)
first_run = first_run_future.result()
# ------------- ///
first_duration = time.time() - t0_first
print('\nfirst async scraper script run time: ',
pd.to_timedelta(first_duration, unit='s'))
# ================================================
# EXTRACT EXPIRYS FROM FIRST RUN SCRAPER
# ================================================
xp = async_option_scraper.expirys(ETFS, first_run)
expirys = xp.get_expirys()
# ================================================
# SCRAPE AND AGGREGATE ALL SYMBOLS BY EXPIRY
# ================================================
t0_xp = time.time()
# -------------- \\\
# dict key=sym, values=list of json data by expiry
# create helper logic to test if expirys is None before passing
sym_xp_dict = {}
ua = UserAgent()
xp_scraper = async_option_scraper.xp_async_scraper()
for symbol in ETFS:
print()
print('-'*50)
print('scraping: ', symbol)
if not expirys[symbol]:
print('symbol ' + symbol + ' missing expirys')
continue
try:
xp_loop = asyncio.get_event_loop()
xp_future = asyncio.ensure_future(
xp_scraper.xp_run(symbol, expirys[symbol], ua.random)
)
xp_loop.run_until_complete(xp_future)
sym_xp_dict[symbol] = xp_future.result()
except Exception as e:
print(symbol + ' error: ' + e)
# ------------- ///
duration_xp = time.time() - t0_xp
print('\nall async scraper script run time: ',
pd.to_timedelta(duration_xp, unit='s'))
# ================================================
# PARSE ALL COLLECTED DATA
# ================================================
t0_agg = time.time()
# -------------- \\\
all_etfs_data = []
for symbol, xp_list in sym_xp_dict.items():
print()
print('-'*50)
print('parsing: ', symbol)
list_dfs_by_expiry = []
try:
for i in range(len(xp_list)):
try:
parser = option_parser.option_parser(
symbol, xp_list[i])
call_df = parser.create_call_df()
put_df = parser.create_put_df()
concat = pd.concat([call_df, put_df], axis=0)
concat['underlyingPrice'] = np.repeat(
parser.extract_last_price(px_dict[symbol]),
len(concat.index))
list_dfs_by_expiry.append(concat)
except: continue
except Exception as e:
print(f'symbol: {symbol}\n error: {e}')
print()
continue
all_etfs_data.append(pd.concat(list_dfs_by_expiry, axis=0))
# ------------- ///
duration_agg = time.time() - t0_agg
print('\nagg parse data script run time: ',
pd.to_timedelta(duration_agg, unit='s'))
# -------------- \\\
dfx = pd.concat(all_etfs_data, axis=0).reset_index(drop=True)
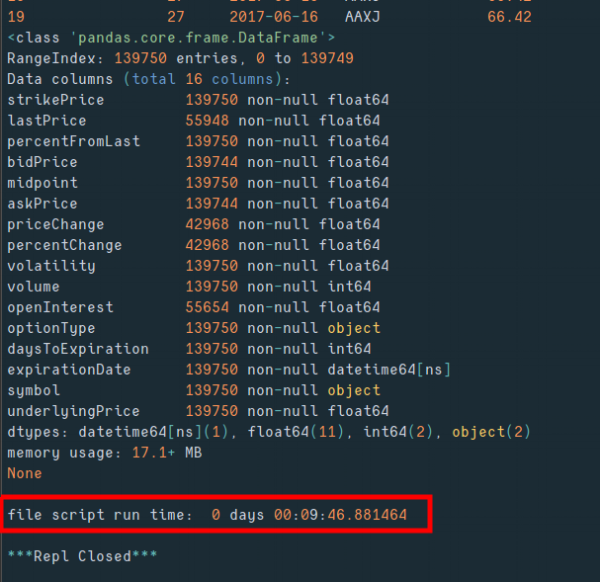
print(dfx.info())
# ------------- ///
# ================================================
# GET ANY MISSING UNDERLYING PRICE
# ================================================
print('\nCollecting missing prices...')
grp = dfx.groupby(['symbol'])['underlyingPrice'].count()
missing_symbol_prices = grp[grp == 0].index
get_price = lambda symbol: web.DataReader(
symbol, 'google', today)['Close']
prices = []
for symbol in missing_symbol_prices:
px = get_price(symbol).iloc[0]
prices.append((symbol, px))
df_prices = pd.DataFrame(prices).set_index(0)
for symbol in df_prices.index:
(dfx.loc[dfx['symbol'] == symbol,
['underlyingPrice']]) = df_prices.loc[symbol].iloc[0]
dfx['underlyingPrice'] = dfx.underlyingPrice.astype(float)
print('\nmissing prices added')
# ================================================
# store dataframe as hdf
# ================================================
print(dfx.head(20))
print(dfx.info())
file_duration = time.time() - file_start
print('\nfile script run time: ', pd.to_timedelta(file_duration, unit='s'))
file_ = project_dir + f'/ETF_options_data_{today}.h5'
dfx.to_hdf(file_, key='data', mode='w')
# ================================================
# kill python process after running script
# ================================================
time.sleep(2)
os.kill(os.getpid(), 9)
Here's some sample output:
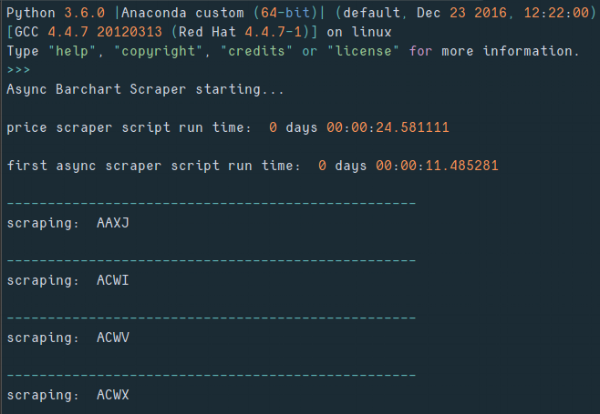
Get the code at the following Github-Gist links:
UPDATE: Here is the list of Nasdaq ETF symbols for download <ETF Symbol List CSV>
References
- Wikipedia.org - AJAX definition
- W3Schools.com - AJAX introduction
- Making 1 Million Requests with Python-aiohttp via https://pawelmhm.github.io - Great article on implementing asyncio with aiohttp
- Barchart.com - "Barchart, the leading provider of market data solutions for individuals and businesses."
