The first job of a serious research system is not to find alpha. It is to create the infrastructure where alpha can be trusted.
Alpha-Lab did not start because I needed another backtester. It started because every new research idea was creating a new software universe: new repo, new collection of tools, new assumptions, new config conventions, new validation habits, and ultimately new ways for results to become incomparable.
That pattern is a bottleneck to creativity. It slows research, fragments knowledge, and blocks the real goal: deploying capital in the market with the intention of getting paid over time.
After repeating the process enough times, you start carrying standards and patterns from project to project. But eventually you hit a crossroads.
There are individual tools and frameworks that handle specific parts of the pipeline. Some are excellent. But after a while, individual tools are not enough. You have to decide whether to commit to an all-in-one vendor platform, with the risks and pricing thresholds that come with it, or build exactly what you want from scratch.
With enough time, experience, and skill, most of us choose the latter. With subsidized AI, that decision becomes even easier.
But after blasting tokens, spending nights bleary-eyed coding, and finally getting the pipeline to run, the danger is not that the code fails. The more dangerous version is that it works well enough to produce results you cannot fully trust.
That is where the real questions begin.
A promising run appears. A backtest looks interesting. A research result looks worth pursuing. But now the system has to answer questions it may not have been built to answer.
In Alpha-Lab, trust means being able to answer:
- Can I reproduce this run?
- Do I know what config produced it?
- Do I know what data version and source it used?
- Do I know whether the result survived walk-forward validation?
- Can I compare this experiment to the last fifty?
- Can I trace performance back to regime, signal, execution, and sizing behavior?
- If it fails live, will I know before the account statement tells me?
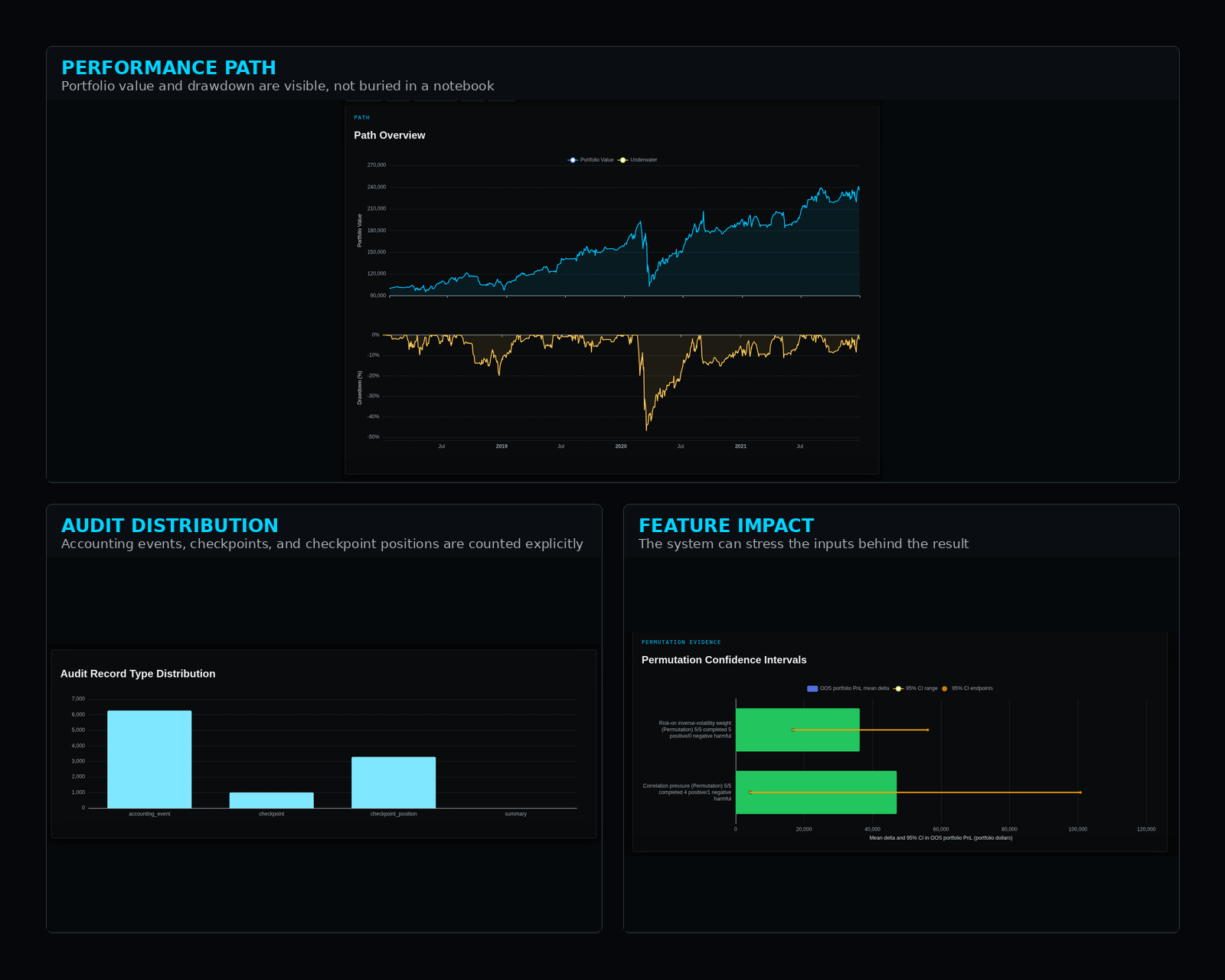
Sports Prediction Machines is the same lesson in a smaller, more focused domain.
Version 1 had the obvious pieces: strategy selection, backtesting, portfolio construction, and analysis. But when I started examining the outputs more rigorously, I realized the audit chain was too weak. I could not query the pipeline deeply enough to understand which parts of the chain impacted the result. System attribution failed.
Alpha-Lab taught the broad version of the lesson. SPM v2 confirmed it.
Trust requires an attributable, auditable system where every input, knob, and lever is intentional, queryable, and traceable.
That is the split behind Forge Learn and Forge Ship.
Forge Learn is for builders who want to learn the full pipeline end to end: research, validation, deployment, execution, and monitoring.
Forge Ship is for builders who want the trust layer: the guardrails, audit structure, and engineering discipline that keep a pipeline from becoming a well-designed machine for producing unverifiable outputs.
Written by hand,
Brian Christopher, CFA
BlackArbs LLC
P.S. If you are building research systems with AI, code, or capital at risk and want to talk through your project, send me a note.